Unveiling the 7 Vs of Data SciencCompiled by: Pratiksha Bishte: A Comprehensive Exploration
Get link
Facebook
X
Pinterest
Email
Other Apps
Unveiling the 7 Vs of Data Science: A Comprehensive Exploration
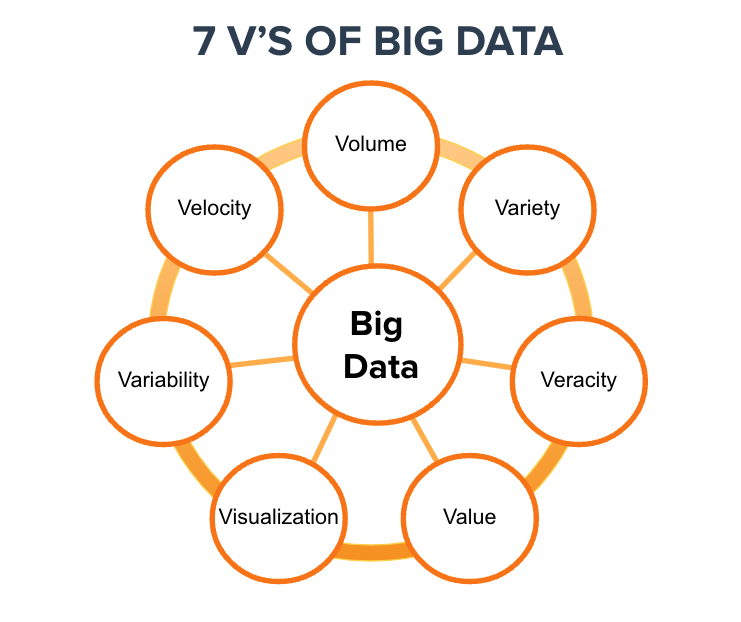
In today's digital age, data has become the lifeblood of numerous industries, driving decision-making, innovation, and growth. The emergence of data science as a field has provided the tools and methodologies to extract insights from this vast ocean of information. To understand the complexity and scope of data science, it's essential to delve into what are commonly referred to as the 7 Vs of data science: Volume, Velocity, Variety, Veracity, Value, Validity, and Vulnerability.
VOLUME
Volume: The first V, volume, refers to the sheer amount of data generated daily. With the proliferation of digital devices, social media platforms, and IoT sensors, data is being generated at an unprecedented rate. This massive volume of data presents both opportunities and challenges for data scientists, as they must develop scalable solutions to store, process, and analyze such vast datasets efficiently.
VELOCITY
2.Velocity: Velocity denotes the speed at which data is generated and processed. In today's real-time world, data streams in rapidly from various sources, requiring data scientists to implement real-time analytics solutions to extract actionable insights promptly. Whether it's monitoring social media trends, analyzing financial transactions, or tracking sensor data, the ability to process data at high velocity is crucial for making timely decisions.
VARIETY
3.Variety: Data comes in various forms, including structured, semi-structured, and unstructured data. This diversity in data types presents a significant challenge for traditional analytics methods. Data scientists must be adept at handling a wide array of data formats, including text, images, videos, sensor data, and more. This requires employing advanced techniques such as natural language processing (NLP), computer vision, and machine learning algorithms capable of processing diverse data types.
VERACITY
4.Veracity: Veracity refers to the accuracy and reliability of data. In the era of big data, ensuring data quality is paramount to derive meaningful insights and make informed decisions. However, data can be noisy, incomplete, or even intentionally misleading, posing significant challenges for data scientists. Hence, data validation, cleansing, and preprocessing techniques are essential to enhance data quality and reliability.
VALUE
5.Value: The ultimate goal of data science is to derive value from data. Organizations invest in data science initiatives with the expectation of gaining actionable insights that lead to improved business outcomes, whether it's optimizing processes, enhancing customer experiences, or driving innovation. Data scientists play a crucial role in uncovering hidden patterns, trends and correlations within data to unlock its inherent value.
VALIDITY
6.Validity: Validity refers to the accuracy and relevance of the insights derived from data analysis. It's essential to ensure that the conclusions drawn from data science models are valid and align with the objectives of the organization. This involves rigorous testing, validation, and evaluation of the models to ascertain their effectiveness and reliability in real-world scenarios.
VULNERABILITY
7.
Vulnerability: As data becomes increasingly valuable, it also becomes a target for malicious actors. Data breaches, cyberattacks, and privacy concerns pose significant threats to the integrity and security of data. Data scientists must be mindful of potential vulnerabilities in data systems and implement robust security measures to safeguard sensitive information,
ensuring compliance with data protection regulations such as GDPR and CCPA.
In conclusion, the 7 Vs of data science encapsulate the multifaceted nature of this rapidly evolving field. From managing massive volumes of data to ensuring its accuracy, relevance, and security, data scientists face myriad challenges in their quest to extract value from data. By understanding and addressing these seven dimensions, organizations can harness the power of data science to drive innovation, gain competitive advantage, and navigate the complexities of the digital landscape.
Introduction: In the modern era of globalization, businesses face increasingly complex challenges in managing their supply chains efficiently. From inventory management to logistics optimization, the need for agile and responsive supply chain processes is paramount. In this context, Artificial Intelligence (AI) has emerged as a game-changer, revolutionizing the way supply chains are managed and operated. This essay explores the transformative impact of AI on supply chain management, highlighting its key applications, benefits, and future prospects. Applications of AI in Supply Chain Management: AI offers a multitude of applications across various stages of the supply chain, enabling organizations to streamline operations, reduce costs, and enhance customer satisfaction. One of the primary applications of AI in supply chain management is demand forecasting. By analyzing historical data, market trends, and external factors, AI-powered algorithms can generate accurate demand forecasts, ...
Title: The Evolution of Artificial Intelligence in Transportation: A Journey into the Future Introduction: Transportation is the lifeblood of modern society, connecting people, goods, and ideas across vast distances. Over the years, advancements in technology have revolutionized the way we travel, from the invention of the wheel to the development of automobiles and airplanes. In recent times, one of the most significant technological leaps has been the integration of artificial intelligence (AI) into transportation systems. This essay explores the role of AI in transforming transportation and its implications for the future. AI in Traffic Management: One of the primary areas where AI is making an impact is in traffic management. Traditional traffic control systems struggle to adapt to dynamic traffic conditions, leading to congestion and inefficiencies. AI-powered traffic management systems, however, can analyze vast amounts of data in real-time, enabling more responsive and adaptive...
Unveiling the Tapestry of Latest Developments in Artificial Intelligence Introduction: Artificial Intelligence (AI) is not merely a field of technology but a rapidly evolving ecosystem that continues to redefine the boundaries of human innovation. Over the past few years, significant advancements have propelled AI into new realms, revolutionizing industries, augmenting human capabilities, and sparking ethical debates. This essay endeavors to explore the latest developments in AI, encompassing breakthroughs in various domains, ethical considerations, and the future trajectory of this transformative technology. Advancements in Machine Learning: Machine learning, a subset of AI, has witnessed remarkable progress, fueled by advancements in algorithms, computing power, and data availability. One notable development is the rise of transformer architectures, such as GPT (Generative Pre-trained Transformer) models, which have demonstrated unprecedented capabilities in natural langu...




Comments
Post a Comment